I’d like to comment on the philosophy of effort, the statistics of diminishing returns, and the intractable conundrum of the intellectual equivalent of quantum superposition. I should explain. I recently came across a page in “The Signal and the Noise” that seemed to epitomize everything about why I’ve been banging my head against the wall for the last month, chasing after rabbits with pocket-watches underground and getting as far as the Red Queen running across an endless chessboard.
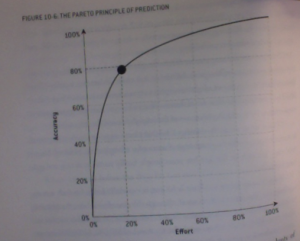
On page 312, Figure 10-6, Mr. 538 Uber-Nerd shows us what he calls the Pareto Principle of Prediction. The basic idea is that with a 20% effort, or experience, 80% accuracy or skill can be acquired. With increasing effort comes increased accuracy, or skill, at diminishing returns yielding a relatively steep log curve. Mr. Silver uses this basic idea to explain his experience with online poker, the possibility of beating the stock market, the fortune to be slightly more prescient than the political geniuses on the McLaughlin Group and Billy Bean’s ability to field a winning team that deserves to be described by their own nickname (“Athletic”s). Unfortunately, he forgot another important example: the ability to beat the poor odds of passing all of your classes while finishing your RA (or TA) work and theoretically writing your MS or PhD proposal. And before you think I’m about to go off on a tirade about how hard my (our) life (lives) is (are), that’s not quite it. We’re all fortunate to be in an incredibly challenging, occasionally inspiring community of mutual learning, teaching and discovering.
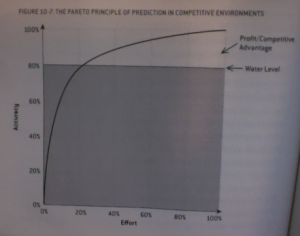
The issue is diminishing returns, and the wisdom to properly divert limited resources to achieve diverse goals. Every day we all confronted with choices, armed with a wide variety of predictor variables (the length of the reading for class, the length of time necessary to properly research this paper we have to write, the number of days until a particular assignment is due) to properly acheive a set of response variables (earn a grade, impress a professor, keep open the possibility of one day walking out of here with a degree). What combination of predictor variables do we need to put into the model in order to accurately achieve our goals? Is Nate suggesting that is we put in 20% of the effort in everything, than we can squeeze by with a B- average in everything, making it just above water level (Figure 10-7)? Is it worth our time to put more effort in a particular area, yielding diminishing returns, and potentially dropping below the water line in a different class, project, thesis?
And therein lies my biggest personal problem. All of us are here because we’re able to acheive intellectually at a fairly high level, and competent enough to divide our time between academics, life-goals and the occasional White Russian on the weekend (the statistician Abides). But maybe some things in life are worth more than a 20% effort, just sliding by. When I study something, research something, invest in something, I want to know, experience the root of the problem, really understand the complexity of the issue. When Jarrett gives us a problem set with five extra credit problems modeling the number of atoms in the universe using R-code that we haven’t really mastered yet, I really really want to figure it out. I want to know the answer. Not for any specific ROI grade objective, really, but because that piece of knowledge reveals something interesting and unique about the universe (or at least I hope). When Dr. Hannigan gives us advanced problem sets in analytical chemistry (I took Natural Waters last semester), I really DO want to be able to calculate the exact atmospheric carbon dioxide concentration during the early Cenozoic based on the chemical equilibria within a single water drop trapped within an Arctic glacial moraine. The problem is that by attempting to attack the problem, I’m putting myself above the 80-20 rule, where increased effort yields progressively decreasingly impressive results. I keep chasing harder and harder problems down the rabbit hole and across the chessboard without appearing to get any closer to checkmate. Meanwhile, Robyn knows exactly which assumptions she can make to negate the majority of differential equations required to solve equilibria conditions, and Jarrett knows exactly which line of code to use to smoothly and efficiently approximate a complex model, while I’m left handing in five homework pages of excessive for loops and fully saturated (and weakly predictive) MLRs.
And so I feel torn between the 17th century French polymath Blaise Pascal and the Eastern guru, his holiness, the 14th Dalai Lama.
“Since we cannot know all that there is to be known about anything, we ought to know a little about everything.” – Blaise Pascal
“We have bigger houses but smaller families: We have more degrees but less sense; more knowledge but less judgements; more experts but more problems; more medicines, but less healthiness. We’ve been all the way to the moon and back, but we have trouble crossing the street to meet the new neighbor. We build more computers to hold more information, to produce more copies than ever, but we have less communication. We have become long on quantity but short on quality. These are times of fast foods, but slow digestion; tall man, but short character; steep profits, but shallow relationships. It is time when there is much in the window but nothing in the room.”
— The Dalai Lama
Should we learn a little about everything as Pascal suggests? Less than 20% of every aspect of our lives in order to stay above the waterline in all of the diverse goals to which we aspire? Or should we pursue the path suggested by the Dalai Lama, who laments modern attempts to do, experience and own everything all at once, leaving one’s center unbalanced and poorly connected? Is it worth attempting all of the extra credit assignments when the regular homework problems are still poorly executed? Those are the questions that stare me in the face when I look at Figure 10-6. I want to know the underlying framework of the scientific field in which I am engaged; I’m sure all of us feel the same way to some extent. But at what cost? At what cost comes spending hours and hours and hours working on a single line of R-code to rise above the 80-20 margin, while leaving laser ablation, dissertation proposals and half-finished manuscripts on the backburner.
Which brings me back to the final enigmatic metaphor that I used way back in the first paragraph of this personal exploration. Quantum theory dictates that a single particle occupies all of its possible quantum states simultaneously. Said in another way, it literally exists everywhere in the universe, all at the exact same time. Crazy. But even crazier is the notion of wave function collapse, where a superposition collapses to a single state (location) of existence after interaction with an observer. As soon as the particle is observed, if no longer exists everywhere, it only exists in one location in space, as is observed in everyday life. Is that our choice, that we can try to understand everything all at once, to invest a tiny tiny bit in everything all across the spectrum of the universe, and not focusing on one specific thing entirely? And that attempt, like superposition, can only exist in the absence of interaction, of being observed? As we so often try to delve into the deepest, most complex theories and problems while in our labs at 2 AM when everyone else has gone home, while we get lost in the vast plateau of excruciatingly incremental achievement above the 80-20 line? And maybe interaction with collegues, like an observed quantum particle, forces us to singularity, where we begin focusing again on more fruitful efforts, below the 80-20 line where incremental increases in effort lead to large leaps in achievement. Maybe I just need to stop working on fifty lines of R code past midnight on a Friday alone in my office.
What I really need, maybe what we all need, is to learn to successfully navigate the 80-20 conundrum of our lives. How should we divide our time? Should we try to do more, with less, or to invest in less, with more effort? Can we balance, like a sub-atomic particle, popping instantaneously between superposition and singularity? Can we dream of becoming leading researchers in our fields while also going home early to cook our own meals in our own homes and spending quality time with the people who mean the most to us in our lives? Maybe it’s not worth trying to jumping above the waterline like a breaching humpback whale when treading water at the 80-20 line allows us to do many diverse things, just ok. And maybe winning the poker hand (grant?) depends on a steady pool of “fish” (failing undergrads, uncreative researchers) as Figure 10-8A suggests. Or maybe it’s not a zero-sum game. Or maybe the cost of living above the 80-20 line (becoming the best in the world at what you do) has it’s own hidden implied costs:
“It’s better to burn out Than to fade away My, my, hey, hey.”
– Neil Young, Kurt Cobain
Thetis: If you stay in Larissa, you will find peace. You will find a wonderful woman, and you will have sons and daughters, who will have children. And they’ll all love you and remember your name. But when your children are dead, and their children after them, your name will be forgotten… If you go to Troy, glory will be yours. They will write stories about your victories in thousands of years! And the world will remember your name. But if you go to Troy, you will never come back… for your glory walks hand-in-hand with your doom. And I shall never see you again.
I know, I know. Now I’m just getting ridiculous. But food for thought. And best wishes navigating your own 80-20 curves, and all of the many sacrifices, and gifts, life has to offer. Good luck!



